Disclaimer
This blog post is a part of NSA Codebreaker 2024 writeup.
The challenge content is a PURELY FICTIONAL SCENARIO created by the NSA for EDUCATIONAL PURPOSES only. The mention and use of any actual products, tools, and techniques are similarly contrived for the sake of the challenge alone, and do not represent the intent of any company, product owner, or standards body.
Any similarities to real persons, entities, or events is coincidental.
Synopsis
Great job finding out what the APT did with the LLM! GA was able to check their network logs and figure out which developer copy and pasted the malicious code; that developer works on a core library used in firmware for the U.S. Joint Cyber Tactical Vehicle (JCTV)! This is worse than we thought!
You ask GA if they can share the firmware, but they must work with their legal teams to release copies of it (even to the NSA). While you wait, you look back at the data recovered from the raid. You discover an additional drive that you haven’t yet examined, so you decide to go back and look to see if you can find anything interesting on it. Sure enough, you find an encrypted file system on it, maybe it contains something that will help!
Unfortunately, you need to find a way to decrypt it. You remember that Emiko joined the Cryptanalysis Development Program (CADP) and might have some experience with this type of thing. When you reach out, he’s immediately interested! He tells you that while the cryptography is usually solid, the implementation can often have flaws. Together you start hunting for something that will give you access to the filesystem.
What is the password to decrypt the filesystem?
Downloads
disk image of the USB drive which contains the encrypted filesystem (disk.dd.tar.gz)
Interesting files from the user’s directory (files.zip)
Interesting files from the bin/ directory (bins.zip)
Prompt
Enter the password (hope it works!)
Solution
So we start off by checking the given files.
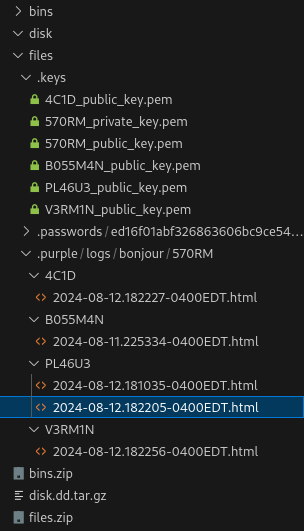
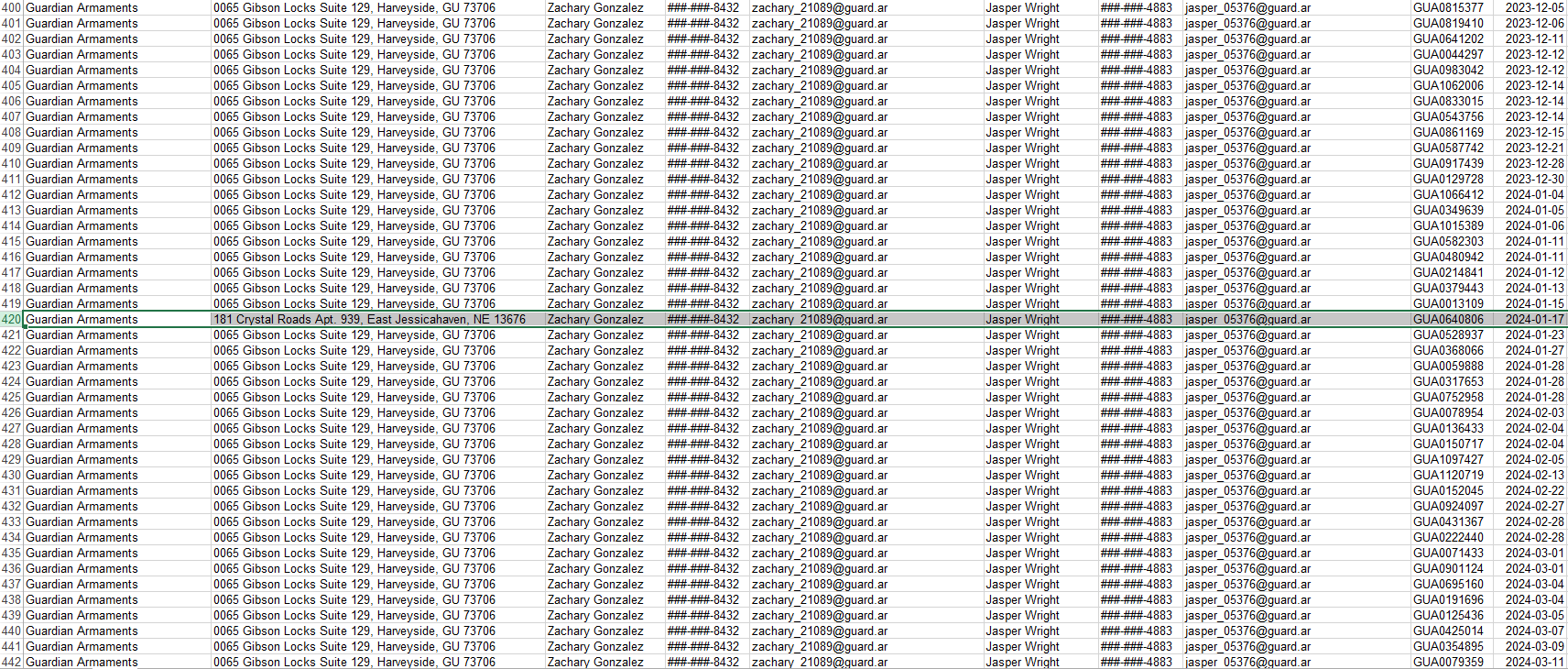
After some poking around, we learned that we are currently doing forensics on workstation of 570RM. We also learned that 570RM sent passwords to 4C1D, PL46U3, and V3RM1N.
Another thing here is we have the public keys of 4C1D, PL46U3, and V3RM1N but not their private keys.
And lastly, we have 570RM‘s private and public key.
Going back to the sent passwords, based on context clues, we assume that they are all the same plaintext but different recipients. We cannot recover the decipher without 4C1D, PL46U3, or V3RM1N‘s private key. However, since we have 3 different ciphertexts of the same plaintexts and their public keys, we might able to recover it! With the power of Chinese Remainder Theorem.
import base64
from Crypto.PublicKey import RSA
import gmpy2
# Function to decode base64 and convert to integer
def decode_ciphertext(encrypted_message):
return int.from_bytes(base64.b64decode(encrypted_message), byteorder='big')
# Decode ciphertexts
c1 = decode_ciphertext("B+QWncX2NQpwUWIA+1+PXw7Y9x7eL53vfixIL+N9dRMG9ZKQnOyZARtV+tG1Zfs3z/r0shpW9fhfA9kOVUw/PGx6UpIRbgRXwKd3EZ0MomhxYXeaaxkXbI2lHfCHOhcWHqsGWgaMsSYxykDe9dX8hPtVeZMwXnGKGcGaZLoQ71WNG9e1kQaMB35UozCrNeqjfrvOJu0A5jIEjZkbaiJkhv01Z9SgE9E8ToCoPU2H/6g0j0j+PnDCjCjvaBS7A2AGP+L3twl3XQmrD8GqM38kIcvvdziZoSZwaB13Uzfzli+LBXKBr9RGjwuleQTeInfSBtW9obW1/I4803mqFj7NvQ==")
c2 = decode_ciphertext("ZtMuN9EjxCv+xtsKAhl1ECIi8wIe3CVC7L1HTTBap73V6MZSEjyEf3Ea7HWyW4juyTp2+PdfDBTBmvvLOYSA2Fm3ydGXBuLav98+7nNMcfEw38x6u9NpbsC0d5qgfhks5tSaFQCkgEHH89T+yrkjT6xkJ5kw64Q+jCVWB2uygzueK5RQbmJO9qRDtiOrxN/I+GW1MLjXpiZiPZcDLnKmBbLLq0P1efakIkkRvIHrbeyyZDRvlUu2d9HLXTVKqsqAh9umxjRKTm24wGbAm1jR9iBFEdGhn2PRDPaUMKEsryjbqzGvcyr1OCr3PS8cQBoejCOLia2L/HtwbRJwMXPEqQ==")
c3 = decode_ciphertext("VRvYIQ3rOrAgQpHyInyBfNpqEHUQJEbTM89+l+Os+3BtInbawuVQ/jc/xjuRQwe40wISJPMnh+uDJZiKn2jQZCWK8AqDZN3I7BXcmvSaSLHJI0lOezlEY/7Ps60wr71YXuozxqhQwJ9dgaNSdAv0BaFPvMN1V5+HGQJfc7VqxvdFpIOq1QwVQwvq9a9HGBaUJRv/sCHDt+EHQtXHNyXJ0U1ox9YqmkOBn+nGVKK5D/WI3iMy8qPYu9F3nGYU4gx644wZSbt8Ks0aTJxKs6TYZPez5+sk0Z7qow8tvKvAXInMb4CH2CsYZnfP8EZD2OG7LpBasSOw6QiE+eL1lkxokw==")
# Extract public keys
public_key1 = RSA.import_key('''-----BEGIN RSA PUBLIC KEY-----
MIIBCAKCAQEArqHDiJwi0hddQv1LCxZcPErAT/WRD6PdUoth/ZNqbv+BZq5JIQJg
AEzeEEqh1Wafv/Ks2fMXAMsslW413zm4Lssk5+os/0JLuUje9OKAhKPTacUt4P74
ZfjDIMOIUfcFmtjcM9nQwY7e/SWXzFeSQsrSp+XdYvB3sCDZtthCUTEtW8hKtPe2
H36K+eyQKzDoMcs/BNV+XiSJoeRK1zDqrOYDNy5Jrob/q4vElEd3BlhCAnlyJg0C
wKSnTrDFDccPWJFM+cPjneSsxTyThWZ8Vr2UcZkcO0VJvFedkb0xUpiTdrHyu9l8
JBqG4CEKs+y941WxoXwNa076GMkmmbCZEQIBAw==
-----END RSA PUBLIC KEY-----''')
public_key2 = RSA.import_key('''-----BEGIN RSA PUBLIC KEY-----
MIIBCAKCAQEAt88A0ixTOgd2GpyA4ihONMkmWyEQ89vvCRVtjtcc/lp3SeXZqLpR
tSIrUt0dsBMVIss+aHrquYs7PkN2FmiHCr+uEa5mB2FvxC04iits7mbYjqoZHpHo
cZAntnSUqW4xVZJEqLh/9L/g/U5WhZ4Ta78eJFpDlo2b/vKPQQ/aBNTmCxedpK6k
KW2EEdND0etrKjh2cl4vHz6d7+OmR3X32QTDBXIjjH+nYU09xrCItfx9s27457sA
yXJ6XY1ry4/DxvAY7yRks4Zd7GynI+kUaXuzhf2WZQIKUc/BrkAnhKaZmb9p+j79
Vx5zefStg4JcFQmAMghbJ3XoUYS6DtaukwIBAw==
-----END RSA PUBLIC KEY-----''')
public_key3 = RSA.import_key('''-----BEGIN RSA PUBLIC KEY-----
MIIBCAKCAQEAyKFLqgFkvwrRt4fBSbDXVjiPdR2jo2vkrUfefAzn7YXmgcy8YM06
SWo3jNVy0/MwrMFwymFHSf31OG3WLcY9epGpg0EP4Ha7go66fy6dv47kTzEnbxSk
o4rMTRiapDFaJRWzGbfZRboS/wuQYTsk+itdMwiFMd3jt5xlDs1ULMQfS/xfcbaR
p1BX5DbdmF45CaoTzv+uBI8piGn5eAFG/Yn3L0L09xDZl5Jtw7JlMeZIo8gzOXE5
HL6eBNZ+1bi4x4dwjXHEFNyeFvbKO4EI8nPk7eRMOyZoPFoY9vrFNVlJxgL4bkaP
RxTQVVtkRsC/FEPq6fKxOnG9odDRtDsfWwIBAw==
-----END RSA PUBLIC KEY-----''')
# Get moduli
n1 = public_key1.n
n2 = public_key2.n
n3 = public_key3.n
# Implementing a custom CRT function
def custom_crt(moduli, residues):
N = 1
for n in moduli:
N *= n
result = 0
for n_i, a_i in zip(moduli, residues):
N_i = N // n_i
# Modular inverse of N_i modulo n_i
inv = gmpy2.invert(N_i, n_i)
result += a_i * N_i * inv
return result % N
# Use the custom CRT function to find x
x = custom_crt([n1, n2, n3], [c1, c2, c3])
# Step 4: Find the cube root of x (since e=3 for Håstad's attack)
m = gmpy2.iroot(x, 3)[0]
# Step 5: Convert the integer m back to bytes
plaintext_bytes = m.to_bytes((m.bit_length() + 7) // 8, byteorder='big')
# Step 6: Strip the PKCS#1 v1.5 padding
if plaintext_bytes.startswith(b'\x00\x02'):
# Find the first occurrence of \x00 after the padding
separator_index = plaintext_bytes.find(b'\x00', 2)
if separator_index != -1:
plaintext_bytes = plaintext_bytes[separator_index + 1:]
# Convert to string and print the recovered plaintext
plaintext = plaintext_bytes.decode('utf-8', errors='ignore')
print("Recovered plaintext:", plaintext)Got it!

We will comeback to this information later. But for now, we need to check other binaries.
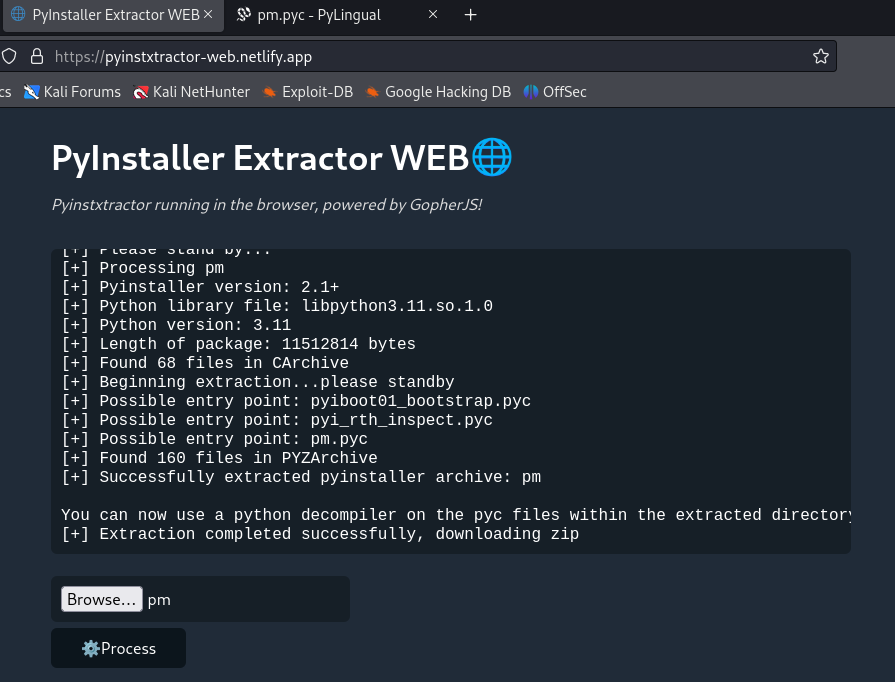
We now shift our focus to pm binary that was under bins.zip. Upon inspecting it, we learned that it was an application built from python. So we use https://pyinstxtractor-web.netlify.app/ to extract the .pyc. After that, we will now use https://pylingual.io/ to convert .pyc to human readable format.
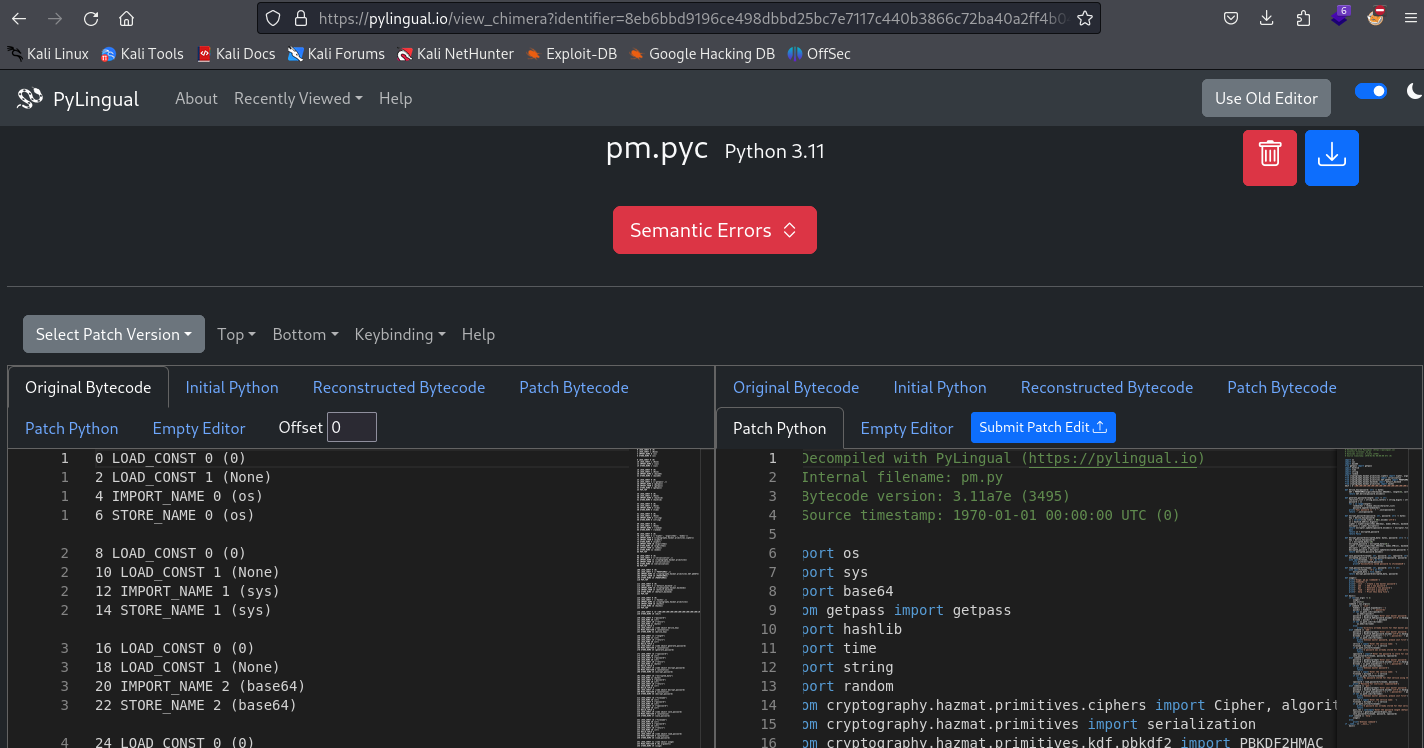
Upon poking, we learned that the password files have a structure of: first 16 bytes are IV, and the rest are the ciphertext. We also aren’t successful in recovering the master password.
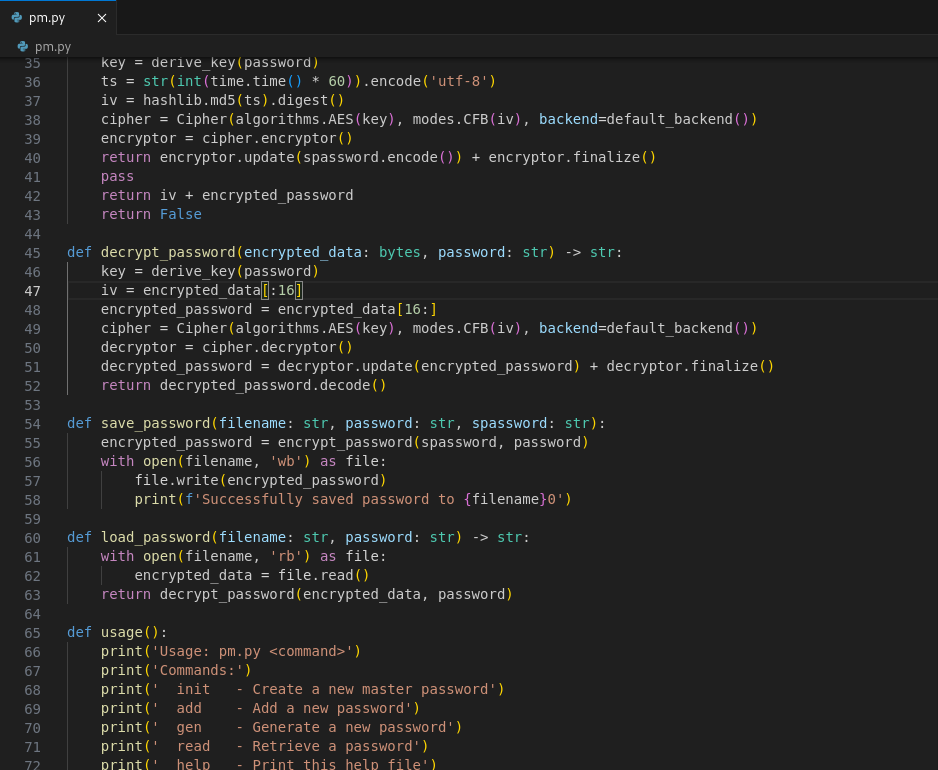
Upon investigating further, we are able to see that AWS and USB password files do have the same key.
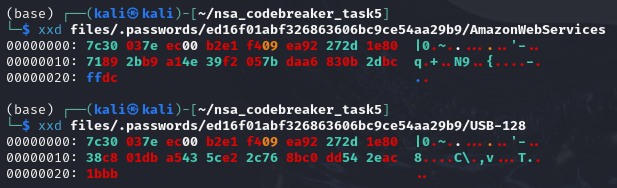
And since we have the ciphertext and IVs of both AWS and USB, and we also have the plaintext of AWS from earlier engagement, then therefore we will be able to use Key Stream Cipher Attack to recover the plaintext of USB.
from Crypto.Cipher import AES
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.backends import default_backend
import hashlib
import time
# Provided data
aws_encrypted = b'\x7c\x30\x03\x7e\xec\x00\xb2\xe1\xf4\x09\xea\x92\x27\x2d\x1e\x80\x71\x89\x2b\xb9\xa1\x4e\x39\xf2\x05\x7b\xda\xa6\x83\x0b\x2d\xbc\xff\xdc'
aws_plaintext = "r2s^PKT=lW2L(wmG06"
usb_encrypted = b'\x7c\x30\x03\x7e\xec\x00\xb2\xe1\xf4\x09\xea\x92\x27\x2d\x1e\x80\x38\xc8\x01\xdb\xa5\x43\x5c\xe2\x2c\x76\x8b\xc0\xdd\x54\x2e\xac\x1b\xbb'
# Extract IV (first 16 bytes)
iv = usb_encrypted[:16]
# Extract ciphertexts (excluding IV)
usb_ciphertext = usb_encrypted[16:]
aws_ciphertext = aws_encrypted[16:]
# Convert plaintext to bytes
aws_plaintext_bytes = aws_plaintext.encode()
# Function to derive the keystream and decrypt usb_ciphertext until non-UTF-8 encountered
def brute_force_until_invalid_utf8(aws_plaintext_bytes, aws_ciphertext, usb_ciphertext):
possible_plaintexts = []
# Brute-force until a non-UTF-8 character is encountered
for length in range(1, len(aws_plaintext_bytes) + 1):
# Derive the partial keystream for the current length
keystream = bytes(c ^ p for c, p in zip(aws_ciphertext[:length], aws_plaintext_bytes[:length]))
# Attempt to recover the usb plaintext using the partial keystream
usb_plaintext = bytes(c ^ k for c, k in zip(usb_ciphertext[:length], keystream))
# Attempt to recover aws plaintext to validate against the original plaintext
aws_recovered = bytes(c ^ k for c, k in zip(aws_ciphertext[:length], keystream))
try:
usb_plaintext_string = usb_plaintext.decode('utf-8')
aws_recovered_string = aws_recovered.decode('utf-8')
# Check if aws_recovered matches aws_plaintext for validation
if aws_recovered_string == aws_plaintext[:length]:
possible_plaintexts.append((length, usb_plaintext_string, aws_recovered_string))
except UnicodeDecodeError:
# Stop if non-UTF-8 character is encountered
break
return possible_plaintexts
# Perform brute-force decryption
decrypted_plaintexts = brute_force_until_invalid_utf8(aws_plaintext_bytes, aws_ciphertext, usb_ciphertext)
# Output all possible plaintexts to a file
with open('usb_plaintext.txt', 'w') as f:
for length, usb_plaintext, aws_recovered in decrypted_plaintexts:
f.write(f"{usb_plaintext}\n")
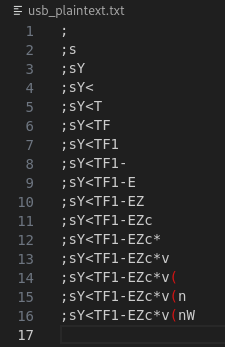
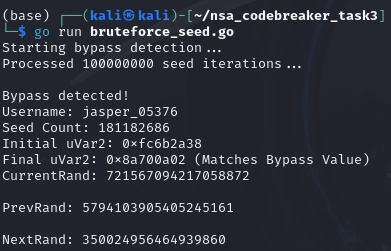
Upon some iterations, I learned that the 17th and 18th characters are non-ascii printable. So there might be some collision happening. So what I did was to create a script to bruteforce the last 2 characters to forcefully unlock the USB.
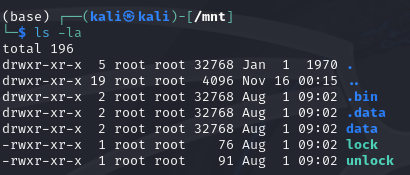
We need to mount the disk.dd first by using the following commands below.

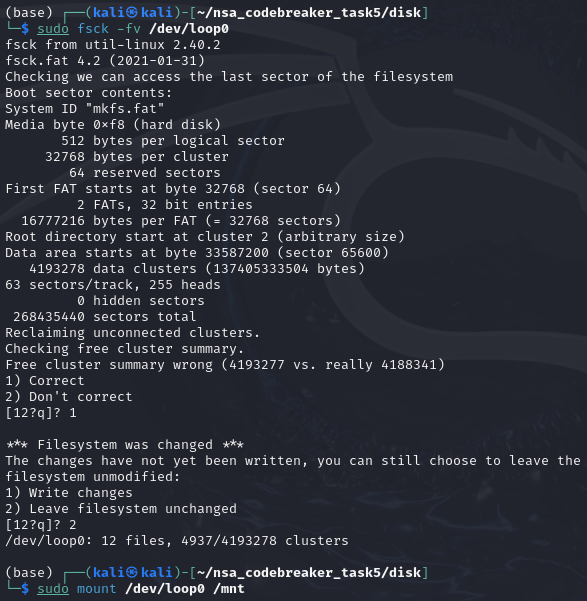
Next, once the disk is mounted, we should now see the unlock and lock binaries.
Now, here is the bruteforce script to unlock the USB content.
import subprocess
import string
import sys
from itertools import product
# Define the fixed prefix of the password
fixed_prefix = ";sY<TF1-EZc*v(nW"
# Character set for brute-forcing the last two characters
charset = string.ascii_letters + string.digits + string.punctuation
# Function to attempt unlocking
def try_password(password):
process = subprocess.Popen(['/mnt/unlock'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout, stderr = process.communicate(input=f"{password}\n".encode())
# Check if the output does not contain "Password incorrect."
if b"Password incorrect." not in stdout + stderr:
return True
return False
# Generate all combinations of two characters from the charset
for combo in product(charset, repeat=2):
# Form the password by appending the brute-forced characters to the fixed prefix
password = fixed_prefix + ''.join(combo)
# Try the password
if try_password(password):
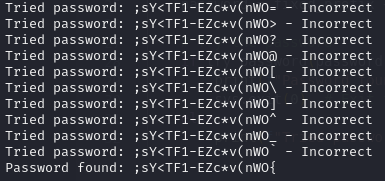
print(f"Password found: {password}")
sys.exit(0) # Exit the script once a valid password is found
else:
print(f"Tried password: {password} - Incorrect")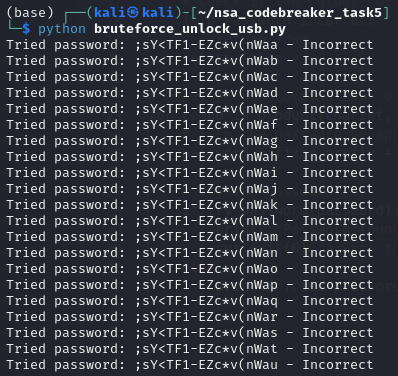
…
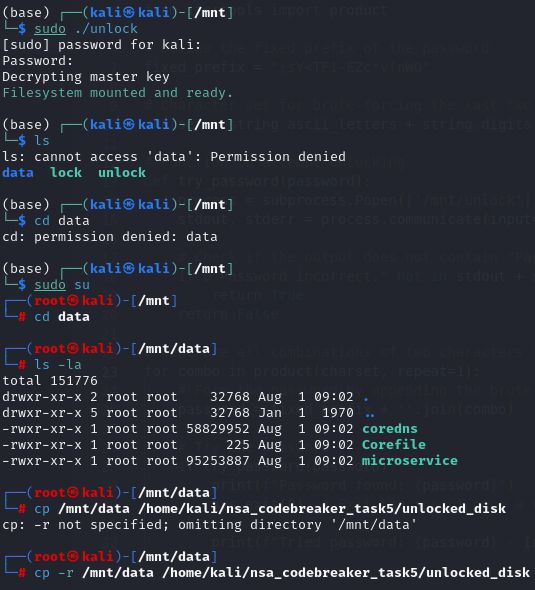
The 3 files are needed for Task 6 and Task 7. The only thing needed to submit to complete the task 5 is the password.